QUE TE PARESE LAS CLASES DE BASE DE DATOS DISTRIBUIDAS
jaime
08-10-2012 09:45
OPINA
CH@RLY
08-10-2012 10:02
pues que las clases fueran mas practicas......
unsharp
08-10-2012 10:30
lo practico seria lo ideal como mencionas....
hola foro 701
unsharp
16-10-2012 08:18
Algo importante seria tambien las reglas de las bases de datos:
Bases de Datos Distribuidas
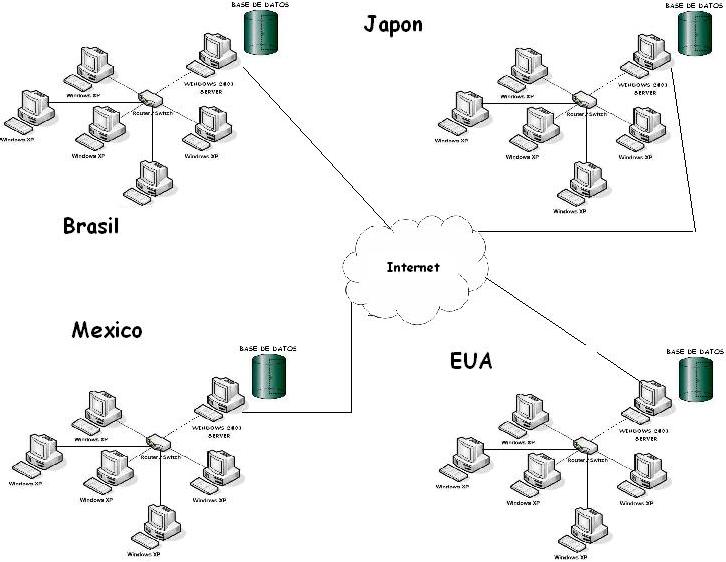
Una Base de Datos Distribuida (BDD) es un conjunto de múltiples bases de datos lógicamente relacionadas las cuales se encuentran distribuidas entre diferentes sitios interconectados por una red de comunicaciones, los cuales tienen la capacidad de procesamiento autónomo lo cual indica que puede realizar operaciones locales o distribuidas. Un sistema de Bases de Datos Distribuida (SBDD) es un sistema en el cual múltiples sitios de bases de datos están ligados por un sistema de comunicaciones de tal forma que, un usuario en cualquier sitio puede acceder los datos en cualquier parte de la red exactamente como si los datos estuvieran
En un sistema distribuido de bases de datos se almacenan en varias computadoras. Los principales factores que distinguen un SBDD de un sistema centralizado son los siguientes:
Hay múltiples computadores, llamados sitios o nodos.
Estos sitios deben de estar comunicados por medio de algún tipo de red de comunicaciones para transmitir datos y órdenes entre los sitios.
Las Doce Reglas de las Bases de Datos Distribuidas:
Principio fundamental : Para el usuario un sistema distribuido debe ser igual que uno centralizado.
Autonomía Local : Los sitios distribuidos deben ser autónomos, es decir que todas las operaciones en un sitio dado se controlan en ese sitio.
No dependencia de un sitio central : No debe de haber dependencia de un sitio central para obtener un servicio.
Operación Continua : Nunca debería apagarse para que se pueda realizar alguna función, como añadir un nuevo sitio.
Independencia con respecto a la localización : No debe de ser necesario que los usuarios sepan dónde están almacenados físicamente los datos, sino que más el usuario lo debe de ver como si solo existiera un sitio local
Independencia con respecto a la fragmentación : La fragmentación es deseable por razones de desempeño, los datos, pueden almacenarse en la localidad donde se utilizan con mayor frecuencia de manera que la mayor parte de las operaciones sean sólo locales y se reduzca el tráfico en la red.
Independencia de réplica : Si una relación dada (es decir, un fragmento dado de una relación ) se puede presentar en el nivel físico mediante varias copias almacenadas o réplicas, en muchos sitios distintos.
Procesamiento Distribuido de Consultas : El objetivo es convertir transacciones de usuario en instrucciones para manipulación de datos, y así reducir el trafico en la red implica que el proceso mismo de optimización de consultas debe ser distribuido.
Manejo Distribuido de Transacciones : Tiene dos aspectos principales, el control de recuperación y el control de concurrencia, cada uno de los cuales requiere un tratamiento más amplio en el ambiente distribuido.
Independencia con respecto al equipo : El SGBDD debe ser ejecutable en diferentes plataformas hardware .
Independencia con respecto al Sistema Operativo: El sistema debe ser ejecutable varios diferentes SO.
Independencia con respecto a la red : El sistema debe poder ejecutarse en diferentes redes.
Todos los usuarios accesan a la BDD a través de un esquema global en forma transparente al usuario. Debe ser posible ejecutar diferentes SGBDD locales que utilicen distintos modelos de datos.
============================================================
Este es un link de una diapositivasen el que explica muy bien al respecto el tema:
===========================================================
Abarcando un poco mas acreca de las bases de datos distribuidas es importante mencionar esto:
Problemas de los sistemas distribuidos
en el que abarca algo importante seria bueno checar la info de abajo....
El rendimiento puede ser peor para el procesamiento distribuido que para el procesamiento centralizado. Depende de la naturaleza de la carga de trabajo, la red, el DDBMS y las estrategias utilizadas de concurrencia y de falla, así como las ventajas del acceso local a los datos y de los procesadores múltiples, ya que éstos pueden ser abrumados por las tareas de coordinación y de control requeridas. Tal situación es probable cuando la carga de trabajo necesita un gran número de actualizaciones concurrentes sobre datos duplicados, y que deben estar muy distribuidos.
El procesamiento de base de datos distribuida puede resultar menos confiable que el procesamiento centralizado. De nuevo, depende de la confiabilidad de las computadoras de procesamiento, de la red, del DDBMS, de las transacciones y de las tasas de error en la carga de trabajo. Un sistema distribuido puede estar menos disponible que uno centralizado. Estas dos desventajas indican que un procesamiento distribuido no es ninguna panacea. A pesar de que tiene la promesa de un mejor rendimiento y de una mayor confiabilidad, tal promesa no está garantizada.
Otro problema a es su mayor complejidad, a menudo se traduce en altos gastos de construcción y mantenimiento. Ya que existen más componentes de hardware, hay más cantidad de cosas por aprender y más interfaces susceptibles de fallar. El control de concurrencia y recuperación de fallas puede convertirse en algo complicado y difícil de implementar, puede empujar a una mayor carga sobre programadores y personal de operaciones y quizá se requiera de personal más experimentado y más costoso.
El procesamiento de bases de datos distribuido es difícil de controlar. Una computadora centralizada reside en un entorno controlado, con personal de operaciones que supervisa muy de cerca, y las actividades de procesamiento pueden ser vigiladas, aunque a veces con dificultad. En un sistema distribuido, las computadoras de proceso, residen muchas veces en las áreas de trabajo de los usuarios. En ocasiones el acceso físico no está controlado, y los procedimientos operativos son demasiado suaves y efectuados por personas que tienen escasa apreciación o comprensión sobre su importancia. En sistemas centralizados, en caso de un desastre o catástrofe, la recuperación puede ser más difícil de sincronizar.
Procesamiento de Consultas
El problema más grande es que las redes de comunicación ( las de larga distancia en especial ) son lentas. El objetivo es reducir al mínimo el tráfico en la red y esto implica que el proceso mismo de optimización de consultas debe ser distribuido, además del proceso de ejecución de las consultas. Es decir un proceso representativo consistirá en un paso de optimización global, seguido de pasos de optimización local en cada unos de los sitios afectados.
Administración de Catálogo
En un sistema distribuido, el catálogo del sistema incluirá no solo la información usual acerca de las relaciones, índices, usuarios, sino también toda la información de control necesaria para que el sistema pueda ofrecer la independencia deseada con respecto a la localización, la fragmentación y la réplica.
Centralizado (" no depender de un sitio central")
Replicas completas (" falta de autonomía, toda la actualización debe ser propagada a cada sitio ")
Dividido ( muy costoso )
Combinación de 1 y 3 (" no depender de un sitio central ").
Propagación de Actualizaciones
El problema básico con la réplica de datos, es la necesidad de propagar cualquier modificación de un objeto lógico dado a todas las copias almacenadas de ese objeto. Un problema que surge es que algún sitio donde se mantiene una copia del objeto puede NO estar disponible, y fracasaría; la modificación si cualquiera de las copias no esta disponible.
Para tratar este problema se habla de " una copia primaria " y funciona así :
· Una de las copias del objeto se designa como copia primaria, y las otras serán secundarias.
· Las copias primarias de los distintos objetos están en sitios diferentes.
· Las operaciones de actualización se consideran completas después de que se ha modificado la copia primaria.
. El sitio donde se encuentra esa copia se encarga entonces de propagar la actualización a las copias secundarias.
Recuperación
Basado en el protocolo de compromiso de dos fases. El compromiso de dos fases es obligatorio en cualquier ambiente en el cual una sola transacción puede interactuar con varios manejadores de recursos autónomos, pero tiene especial importancia en un sistema distribuido porque los manejadores de recursos en cuestión ( o sea los DBMS locales ) operan en sitios distintos y por tanto son muy autónomos. En particular, son vulnerables a fallas dependientes. Surgen los siguientes puntos :
El objetivo de "no dependencia de un sitio central" dicta que la función de coordinador no debe asignarse a un sitio específico de la red, sino que deben realizarla diferentes sitios para diferentes transacciones. Por lo regular se encarga de ella el sitio en el cual se inicia la transacción en cuestión.
El proceso de compromiso en dos fases requiere una comunicación entre el coordinador y todos los sitios participantes, lo cual implica más mensajes y mayor costo extra.
Si el sitio Y actúa como participante en un proceso de compromiso en dos fases coordinado por el sitio X, el sitio Y deberá hacer lo ordenado pro el sitio X ( compromiso o retroceso, según se aplique ), lo cual implica otra pérdida de autonomía local.
En condiciones ideales, nos gustaría que el proceso de compromiso en dos fases funcionara aun en caso de presentarse fallas de sitios o de la red en cualquier punto. Idealmente, el proceso debería ser capaz de soportar cualquier tipo concebible de falla. Por desgracia es fácil ver que este problema es en esencia imposible de resolver; es decir, no existe un protocolo finito que garantice el compromiso al unísono de una transacción exitosa por parte de todos los agentes, o el retroceso al unísono de una transacción no exitosa en caso de fallas arbitrarias.
Concurrencia
Este concepto tiene que ver con la definición de un agente. El manejo de transacciones tiene dos aspectos principales, el control de recuperación y el control de concurrencia. En un sistema distribuido, una sola transacción puede implicar la ejecución de código en varios sitios ( puede implicar actualizaciones en varios sitios ), entonces se dice que una transacción esta compuesta por varios agentes, donde un agente es el proceso ejecutado en nombre de una transacción dada en determinado sitio. Y el sistema necesita saber cuando dos agentes son parte de la misma transacción.